definition
SSA
dominator frontier
dominator
Phi node insert
Ref: http://www.cis.upenn.edu/~cis570/schedule.html
2011年8月24日 星期三
Introduction to Data-flow Analysis lecture 04 class
Control-Flow Analysis lecture 03 @ class
2011年8月23日 星期二
good compiler class
http://www.cis.upenn.edu/~cis570/schedule.html
http://web.cecs.pdx.edu/~mperkows/
http://web.cecs.pdx.edu/~mperkows/CLASS_574/index.html
http://www.cs.ucla.edu/~palsberg/
ps: 其實把key word 打上 Google, 應該就有一堆東西撈不完了.
對我這個半路出家的人來說,真是受益良多.
http://web.cecs.pdx.edu/~mperkows/
http://web.cecs.pdx.edu/~mperkows/CLASS_574/index.html
http://www.cs.ucla.edu/~palsberg/
ps: 其實把key word 打上 Google, 應該就有一堆東西撈不完了.
對我這個半路出家的人來說,真是受益良多.
Loop unswitching
# Original
# int i, w, x[1000], y[1000];
# for (i = 0; i < 1000; i++) {
# x[i] = x[i] + y[i];
# if (w)
# y[i] = 0;
# }
#
#----------------------------------
# Loop unswitching
#
# int i, w, x[1000], y[1000];
# if (w) {
# for (i = 0; i < 1000; i++) {
# x[i] = x[i] + y[i];
# y[i] = 0;
# }
# } else {
# for (i = 0; i < 1000; i++) {
# x[i] = x[i] + y[i];
# }
# }
1.可確保在for loop 中的 lp_body 是 clean 的,
表示在 lp_body 中,只有 DFG 的 (BasicBlock)BB, 可避免不必要的條件中斷(Branch).
2.可透過 struct 的分析,把 for loop 當成個 node, 可以簡化成 sample BB with CFG control.
之後利用 BDD (Binary decision diagram) 的方式做出每個 Output condition 的機率,
有利於 compiler 做 branch jump 的 predict
x1,x2,x3,Y
---------
[0,0,0] = 0
[0,0,1] = 0
[0,1,0] = 1
[0,1,1] = 1
[1,0,0] = 1
[1,0,1] = 1
[1,1,0] = 1
[1,1,1] = 0
@ y = 0 prb(3/8)
@ y = 1 prb(5/8) <= predict better
3. key notes
判斷 condition branch 是否 stable, 會不會在 for loop 內改變狀態, 如果是 stable 才做 Loop unswitching
'<'+'br'+'>' problems
最近被Blogger的排版設定給氣死,沒事把換行符號給設定死,
害我的排版變得有時候換行,有時候沒有換行...真是他XXX的好.
各位看官就將就將就一下吧,目前已經設定改好,我想之後的 post 排版應該會好看些.
ps: 可以在設定那邊選取,是否每次換行時加入'<'+'br'+'>' 的選項
Ref: http://blog.grovehillsoftware.com/2009/04/blogger-causing-problems-for.html
害我的排版變得有時候換行,有時候沒有換行...真是他XXX的好.
各位看官就將就將就一下吧,目前已經設定改好,我想之後的 post 排版應該會好看些.
ps: 可以在設定那邊選取,是否每次換行時加入'<'+'br'+'>' 的選項
Ref: http://blog.grovehillsoftware.com/2009/04/blogger-causing-problems-for.html
2011年8月22日 星期一
unroll loop
#
# for(i=0; i<2; i++) {
# c[i] = a[i] + a[i+1];
# }
#
#----------------------------
#
# c[0] = a[0] + a[1];
# c[1] = a[1] + a[2];
#
#----------------------------
# @ deepest loop case without subloop loop *lp =
cfg->get_LoopInfo();
Condition *cond = lp->get_Condition();
loop_node *Entry = lp->get_LoopEntry();
loop_node *Body = lp->get_LoopBody();
loop_node *Exit = lp->get_LoopExit();
#loop lp->get_SubLoops();
faltList<> = cond->get_Flattens();
int run_size = do_run_size();
InstructionList<> = Body->get_Instructions();
tmp_InstructionList = [];
for(int i =0; iget_Operand_Src1();
Operand *src2 = (Instruction)ii->get_Opernad_Src2();
Operand *dst = (Instruction)ii->get_Opernad_Dst();
Operator *op = (Instruction)ii->get_Operator();
if( src1->isArrayAccess() && faltList.find(src1->get_Array_ID()) != faltList.end() ) {
int new_src1_inx = faltList.find(src1->get_Array_ID())->get_Lists()->get_Value(i) +
src1->get_Array_ID()->get_Offset();
Operand *new_src1 = new Operand(src1->get_Array(),new_src1_inx);
}
if( src2->isArrayAccess() && faltList.find(src2->get_Array_ID()) != faltList.end() ) {
int new_src2_inx = faltList.find(src2->get_Array_ID())->get_Lists()->get_Value(i) +
src2->get_Array_ID()->get_Offset();
Operand *new_src2 = new Operand(src2->get_Array(),new_src2_inx);
}
if( dst->isArrayAccess() && faltList.find(dst->get_Array_ID()) != faltList.end() ) {
int new_dst_inx = faltList.find(dst->get_Array_ID())->get_Lists()->get_Value(i) +
dst->get_Array_ID()->get_Offset();
Operand *new_dst = new Operand(dst->get_Array(),new_dst_inx);
}
Instruction *new_ii = new Instruction(new_dst,new_src1,op,new_src2);
tmp_InstructionList.push(new_ii);
}
}
BasicBlock *lp_pre = Entry->get_Proc();
BasicBlock *lp_nxt = Exit->get_Succ();
cfg->del_Loop_BB([Entry,Pre_Header,Header,Body,Exit]);
cfg->del_Loop_Edge([{lp_pre,Entry},{Entry,Pre_Header},{Pre_Header,Header},{Header,Body},{Body,Exit},{Exit,Header}]);
BasicBlock *bb_entry = new BasicBlock();
BasicBlock *bb_exit = new BasicBlock();
BasicBlock *bb_cont = new BasicBlock();
cfg->set_BasicBlock([bb_entry,bb_exit,bb_cont]);
cfg->set_Edge([{lp_pre,bb_entry},{bb_entry,bb_cont},{bb_cont,bb_exit},{bb_exit,lp_nxt}]);
foreach ii in tmp_InstructionList
bb_cont.set_Instruction(ii);
# { i:[0,1], ... }
int do_run_size() {
int num = 0;
foreach flat in faltList {
foreach id in flat->get_IDs() {
if ( num == 0 )
num = id->get_Lists().size()
else
assert( id->get_Lists().size() == num && "size error in loop condition" );
}
}
return num;
}
2011年8月21日 星期日
BDD (Binary decision diagram)
binary decision tree.以前唸書的時候,邏輯設計課要學卡諾圖(Karnaugh map)化簡,不過現在有一個比較好用的tool,BDD(binary decision diagram)可以幫我們判斷出條件 Path 的路徑 跟 Output 的 case 解.當然這也可以分析出 code 的 condition coverage 跟做些 reduction 的 methods.
可參考底下的教學跟安裝.
Refs:
http://en.wikipedia.org/wiki/Binary_decision_diagram
http://lyle.smu.edu/~bxu/SimpleADD.html
2011年8月19日 星期五
pre_header
#
# for (int i=0; i<10; i++) {
# c = a + b + i;
# }
#
#------------------------------
# i = 0;
# do {
# j = a + b
# c = j + i;
# i++;
# } while(i<10)
#
# @ predict jump
#-------------------------------
#
# loop(entry):{}
# loop(lp_eader):{ i=0; }
# loop(lp_body):{ j=a+b; c=j+i; i=i+1; }
# loop(lp_exit):{ i<10; }
# loop(exit):{}
#
# E0:{loop(entry)->loop(lp_header)}
# E1:{loop(lp_header)->loop(lp_body)}
# E2:{loop(lp_body)->loop(lp_exit)}
# E3:{loop(lp_exit)->loop(lp_body)}
# E4:{loop(lp_exit)->loop(exit)}
#------------------------------
# j = a + b;
# for (int i=0; i<10; i++) {
# c = j + i;
# }
#------------------------------
#
# j = a + b;
# i = 0;
# do {
# c = j + i;
# } while(i<10)
#
# loop(entry):{}
# loop(lp_pre_header):{ j=a+b; }
# loop(lp_header):{ i=0; }
# loop(lp_body):{ c=j+i; i=i+1; }
# loop(lp_exit):{ i<10; }
# loop(exit):{}
#
# E0:{loop(entry)->loop(lp_pre_header); }
# E1:{loop(lp_pre_header)->loop(lp_header); }
# E2:{loop(lp_header)->loop(lp_body); }
# E3:{loop(lp_body)->loop(lp_exit); }
# E4:{loop(lp_exit)->loop(lp_header); }
# E5:{loop(lp_exit)->loop(exiy); }
loop *lp = cfg->get_LoopInfo();
loop_node *entry = lp->get_LoopEntry();
loop_node *exit = lp->get_LoopExit();
loop_node *header = lp->get_LoopHeader();
loop_node *body = lp->get_LoopBody();
InstructionList<> = body->get_Instructions();
pre_header_list = [];
foreach ii in InstructionList {
if ( ii->isMoveAble2PreHeader() )
pre_header_list.push(ii);
}
if ( !pre_header_list.empty() ){
loop *pre_header = new loop();
cfg->set_Loop(pre_header);
entry->del_Succ(header);
entry->set_Succ(pre_header);
pre_header->set_Succ(header);
pre_header->set_Proc(entry);
header->del_Proc(entry);
header->set_Proc(pre_header);
foreach ii in pre_header_list {
pre_header->set_Instruction(ii);
header->del_Instruction(ii);
}
}
bool isMoveAble2PreHeader() {
OperandList<> = Instruction(this)->get_Operands();
bool change = true;
foreach op in OperandList {
if( (Operand)op != result ) {
if( (Operand)op->get_Parent() != loopInfo && (Opernand)op->isStable() )
change &= true;
else
change &= false;
}
}
return change;
}
form wiki definition:
loop pre-header
Suppose block M is a dominator with several incoming edges, some of them being back edges (so M is a loop header). It is advantageous to several optimization passes to break M up into two blocks Mpre and Mloop. The contents of M and back edges are moved to Mloop, the rest of the edges are moved to point into Mpre, and a new edge from Mpre to Mloop is inserted (so that Mpre is the immediate dominator of Mloop). In the beginning, Mpre would be empty, but passes like loop-invariant code motion could populate it. Mpre is called the loop pre-header, and Mloop would be the loop header.
refs: http://en.wikipedia.org/wiki/Control_flow_graph
cycle graph
DataFlowGraph *dfg DataFlowGraph();
dfg = dfg->run_Structure_analysis(); # reduce dead code
dfg = dfg->run_LoadStore_analysis(); # reduce memory access
dfg = dfg->run_reSchedule_analysis(); # parallel / serial
dfg = dfg->run_Hardware_analysis(); # SIMD / MIMD ...
assert( dfg->run_Pass() && "run BB analysis fail" );
# assignment cycle graph for each BB
#
BasicBlockList<> = dfg->get_BasicBlocks();
float tmp_time;
while ( !BasicBlockList.empty() ) {
(BasicBlock) bb = BasicBlockList.pop();
tmp_time = 0;
float { start_time:0, end_time:0 } = bb->init_time();
tmp_time = start_time;
foreach (Instruction)ii in bb->get_Instructons() {
tmp_time = max(tmp_time + ii->get_Operate_time(), tmp_time);
if( tmp_time > Clock_Freq ) {
bb->set_end_time = ( tmp_time - ii->get_Operate_time() );
BasicBlock *new_bb = dfg->split_BB(bb,ii);
if( dfg->run_Pass() && "split_BB fail" );
# split BB before ii, update "nALive", "outALive" for old.new BB
BasicBlockList.push(new_bb);
}
}
}
# cycle graph schdule
#
dfg->run_ASAP_schedule();
dfg->run_ALAP_schedule();
dfg->run_Force_Directed_schedule();
# Hardware export
#
dfg->Module_export();
dfg->Interface_export();
dfg->Register_export();
dfg->Memory_export();
dfg->FSM_export();
dfg->DataPath_export();
dfg->Linker_export();
dfg->test_bench_export();
2011年8月17日 星期三
SSA (static single assignment)
DataFlowGraph *dfg = DataFlowGraph([]);
foreach (BasicBlock)bb in (DataFlowGraph)dfg->get_BasicBlocks() {
foreach (BasicBlock)preProc in (BasicBlock)bb->get_PreProcessor() {
pre_aLiveOutList = preProc->get_aLiveOutRegs();
foreach (Register)inReg in (BasicBlock)bb->get_aLiveInRegs() {
if( pre_aLiveOutList.find(inReg) != Pre_aLiveOutList.end() ) {
(Register)OutReg = preProc->get_Reg(inReg->get_ID());
if( !PHI_Exist(OutReg,InReg) ) {
# deep copy the old register items 2 new register, such as "procs", "succs"...
{ new_OutReg, new_InReg } = PHI_Insert(OutReg,InReg);
# remove the old register pointer
bb->remove_reg(InReg);
bb->set_reg(new_InReg);
# update the graph
preProc->remove_reg(OutReg);
PreProc->set_reg(new_OutReg);
}
}
}
}
}
#########################
# B1:{ a=1; }; B2:{ a=2; }; B3:{ a=a+1; }
# E1:{B1->B3}; E2{B2->B3};
#
# SSA graph
# B1: { a(1)=1; }; B2:{ a(2)=2; }; B3:{ phi a(3):[ B1:a(1), B2:a(2)]; a(3)=a(3)+1; }
Refs:
SSA wiki
http://en.wikipedia.org/wiki/Static_single_assignment_form
Use-define_chain for load store
http://en.wikipedia.org/wiki/Use-define_chain
2011年8月16日 星期二
sample compiler flow
寫了個 sample compiler flow,不過這裡面還有很多議題可以討論,就等小弟我慢慢的研究吧.
CFG *cfg = Parser(['file','code','temp_IR']);
# Blocks[BB(basicblock)];
# Edges [forward,backward,cross,tree,fallthrough(without branch condition)];
# SubGraph(DFG): data flow graph ex: c = a + b;
#
# @ ex: if ( a==1 ) { c = a+b; } else { c = a-b; }
#
# cfg_BB(0); # condition
# cfg_BB(0)->dfg_BB(0) # a==1
# dfg_BB(0)->instruction_ii(0) # a==1
# instruction_ii(0)->operator(0)[label,type,operand] # int(a) eq 1
# cfg_BB(1): #If(true)
# ...
# cfg_BB(2): #If(false)
# ...
# cfg_EE(0){cfg_BB(0),cfg_BB(1),'E0',0}; # edge 'E0' weighted 0 cfg_BB(0)->cfg_BB(1)
# ...
# linklist gen
list<>cfg_order = cfg->search_methods([deep_first_search(),
breadth_first_search(),
post_order_search(),
pre_order_search(),
topology_sequence_search(),
reverse_topology_sequence_search()]);
# cfg_order = [ cfg_BB(0), cfg_BB(1), cfg_BB(2) ];
# find domin path, check dependence for each BasicBlock
Dom *dom_tree = Dom(cfg);
list<>dom_order = dom_tree->search_methods([post_order_domin(),
pre_order_domin(),
imm_domin()]);
# dom_order = { Dom(cfg_BB(0):{cfg_BB(0)}),
Dom(cfg_BB(1):{cfg_BB(0),cfg_BB(1)}),
Dom(cfg_BB(2):{cfg_BB(0),cfg_BB(2)}) };
Dom_Graph *dom_graph = dom_tree->gen_graph();
# cfg_BB(0) @ dom_graph(directed graph)
# |
# -----------
# | |
# V V
# cfg_BB(1) cfg_BB(2)
# find the correlation for each instruction
Reg *reg = Reg(cfg);
list<>reg_bb_order = reg->search_SSA();
# reg_bb_order = { BB0:[ cfg_BB(0)->dfg_BB(0)->(a:0), cfg_BB(0)->dfg_BB(0)->(eq:0), cfg_BB(0)->dfg_BB(0)->(1:0) ],
# BB1:[ cfg_BB(1)->dfg_BB(1)->(c:1), cfg_BB(1)->dfg_BB(1)->(add:1), cfg_BB(1)->dfg_BB(1)->(a:1), cfg_BB(1)->dfg_BB(1)->(b:1) ],
# BB2:[ cfg_BB(2)->dfg_BB(2)->(c:2), cfg_BB(2)->dfg_BB(2)->(sub:2), cdg_BB(2)->dfg_BB(2)->(a:2), cfg_BB(2)->dfg_BB(2)->(b:2) ] }
SSA_Graph *ssa_graph = reg->toSSA();
# (a:0) eq (1:0)
# |
# --------------------------
# | |
# V V
# (c:1) add (a:1) (b:1) (c:2) sub (a:2) (b:2)
list<> phi_order = ssa_graph->search_PHI(c);
# phi_order = [ BB1:c:1, BB2:c:2 ] @ node c
#CFG *nw_cfg = ssa_graph->toCFG();
# static analysis for BasicBlock such as if else, while, ...
Strc *strc_tree = Strc(cfg);
strc_tree->search_methods([Block(),
IfThen(),
IfThenElse(),
SelfLoop(),
NaturalLoop(),
Unreachable()]);
strc_tree->analysis([DeadCodeCut(),
LoadStroeMerge(),
ParallelMerge(),
SerialMerge()])
# DeadcodeCut ex: for(i=0; i<10; i++) { a=1; } unreachable @ a=1;
# LoadStoreMerge ex: c = a[10]; c = a[10];
# a[10] = c+1; = d = c+1;
# d = a[10];
# SerialMerge ex: BB(0) goto BB(1) @ if and only if BB(0)->BB(1) has one directed edge and BB(1) has only one sink edge.
# merge BB(0) and BB(1) to BB(0-1)
# ParallelMerge ex: BB(0) and BB(1) are dependent @ if and only if Dom(BB(0)) != Dom(BB(1)), path(BB(0)) != path(BB(1))
# BB(0) BB(1) can be parallel
cfg = str_tree->update_cfg();
# find Branck location, and predict it happened or not,
Div_Graph *div_graph = Div_Graph(cfg);
div_graph->analysis([BranchPredict(),
BranchCut()]);
# ex: if ( a==1 ) { if( b==1 ) { c=a+b; } }
# |
# if( a==1 && b==1 ) { c=a+b; }
cfg = div_graph->update_cfg();
# platform Assignment
# X86/Arm/Mips...
X86 *x86 = X86(cfg);
# x86 SIMD analysis, ex: MAC d = (a*b)+c merge a = a*b and d = a+c
x86->analysis_SIMD();
...
ref: Muchnick book
2011年8月14日 星期日
Dominator tree @ A simple and fast dominance algorithm
在 compiler 中,為了要分析出 data 彼此間的相依關係, 可以透過 dominator tree 的方式來解決. 假設
a(b) & b(a) = b dom in a & a dom in b; #a = b,
a(b) & b(c) = b dom in a & c dom in b; # a(c) c dom in a
a(b) & c(b) = b dom in a & b dom in a; # a != b
...
當然也可以解決 loop 的問題, 之後可建立起 block graph + SSA(static single assignment) graph, 來做些 merge 跟 code reduction 的動作.
Dominator tree
refs:
^ Cooper, Keith D.; Harvey, Timothy J; and Kennedy, Ken (2001). "A Simple, Fast Dominance Algorithm". http://www.hipersoft.rice.edu/grads/publications/dom14.pdf.
http://en.wikipedia.org/wiki/Dominator_%28graph_theory%29
View more presentations from sean chen.
2011年8月11日 星期四
open course @ college
http://videolectures.net/mit_ocw/
最近在看 open course wave 順便學一下聽力跟複習一下之前所交過的東西,只能說以前大學時候真的是太"混"了,看來該來的還是要還的阿.XD
 Lecture 1: Goals of the course; what is computation; introduction to data types, operators, and variables
Eric Grimson
refs:
http://ocw.mit.edu/courses/
http://en.wikipedia.org/wiki/Open_educational_resources
Lecture 1: Goals of the course; what is computation; introduction to data types, operators, and variables
Eric Grimson
refs:
http://ocw.mit.edu/courses/
http://en.wikipedia.org/wiki/Open_educational_resources
Lecture 1: Goals of the course; what is computation; introduction to data types, operators, and variables
Eric Grimson
refs:
http://ocw.mit.edu/courses/
http://en.wikipedia.org/wiki/Open_educational_resources
2011年8月9日 星期二
python tutorial @ Goolge
如果你夠懶, 且英文也不錯, 對 Python 也有興趣, 相信底下的 link 對於"初學者"有很大的幫助, 當然我也是一邊看一邊去官網查 DOC, 彼此共勉之吧...其他部分就請去 youtube google 一下吧.
2011年8月7日 星期日
Latch design & filter ....
 一般在 Design 時,都會避免使用到 latch, 之所以如此, 最主要的原因還是在 "Debug", 因為 latch 是 Level sensitive, 一但多個 level trigger 會使得 Data 的狀態一直在改變. 但 latch 也不是毫無用處, 因為有時會為了偷時間, 會在 critical path 上插入 latch 來 meet design.
一般在 Design 時,都會避免使用到 latch, 之所以如此, 最主要的原因還是在 "Debug", 因為 latch 是 Level sensitive, 一但多個 level trigger 會使得 Data 的狀態一直在改變. 但 latch 也不是毫無用處, 因為有時會為了偷時間, 會在 critical path 上插入 latch 來 meet design.
 ex: flip flop 2 latch(1.5T) + latch 2 flip flop (0.5T) for 2T design. or multi clock design... 雖然說可以用 mix up(TetraMax) 的方式把不同 clock domain 串起來,如 111222(@ clock 1 to clock 2), 而不是 121212(clock to clock2 to clock1)的方式,但實際在run ATPG 時, 一般都會把這種的 path 給 mask 掉, 相對的所測的 test case 是不是變少了, 雖然說可以用 feedback 的方式把 flip flop 的 Q 接回 D 來測倍頻, 但 test case 不是倍頻的話,要怎嚜測呢?. 似乎可以透過 STA 把 latch 想成 flip flop, 把 path 1 (flip 2 latch) 的 slack 跟
path 2 (latch 2 flip) 的 slack 相比, 是否就可以算出 barrow time, 在去驗證這時間點的 pattern, 不過最暴力的方式,還是打 functional pattern.
Latch sample code.
http://kb.cnblogs.com/a/1264292/
refs:
ex: flip flop 2 latch(1.5T) + latch 2 flip flop (0.5T) for 2T design. or multi clock design... 雖然說可以用 mix up(TetraMax) 的方式把不同 clock domain 串起來,如 111222(@ clock 1 to clock 2), 而不是 121212(clock to clock2 to clock1)的方式,但實際在run ATPG 時, 一般都會把這種的 path 給 mask 掉, 相對的所測的 test case 是不是變少了, 雖然說可以用 feedback 的方式把 flip flop 的 Q 接回 D 來測倍頻, 但 test case 不是倍頻的話,要怎嚜測呢?. 似乎可以透過 STA 把 latch 想成 flip flop, 把 path 1 (flip 2 latch) 的 slack 跟
path 2 (latch 2 flip) 的 slack 相比, 是否就可以算出 barrow time, 在去驗證這時間點的 pattern, 不過最暴力的方式,還是打 functional pattern.
Latch sample code.
http://kb.cnblogs.com/a/1264292/
refs:
Latches and timing closure: a mixed bag
Latches can improve both the area and performance of your design, but they do create complexities in timing closure.
Selecting clock skews at advanced nodes
Minimizing clock skew across the network may result in high power and timing difficulties. This paper suggests careful selection of clock skews.
2011年8月3日 星期三
sample simulation env
底下寫了個 pseudo code for sample simulation.主要建立起每個 Signal 的 class. 在依序填入 Signallist 中,之後根據現在的 time cycle 取得 runnable 的 Signal, 取得 Signal 後,根據其 Driver 的 Method 做動作.如果其 Method 會 Driver 到其他的 input/inout Signal, 再把其 Driver 的 Signal 填入 Signallist 中,再重新 Sort 一次,直到這次的 Cycle 內的所有 Signals 都以完成.
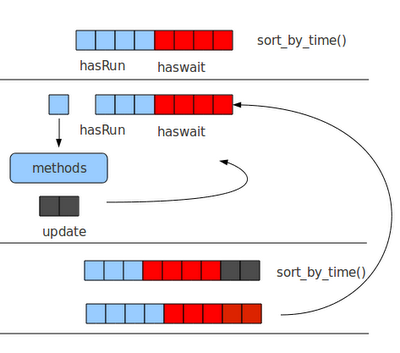

# Sample.v
# module Sample(clk,rst,a,c)
# input clk,rst;
# intput a[31:0];
# output c[31:0];
# reg b[31:0];
#
# assign c = (b==10)? b+a : a;
#
# always@ (posedge clk or posedge rst) begin
# if (rst==1'b1)
# b <= 0;
# else
# b <= b + 1;
# end
# endmodule
#
# test_Sample.v
# always
# #10 clk ~= clk
#
# initial begin
# #0 Rst = 1'b0;
# #5 Rst = 1'b1;
# #20 Rst = 1'b0;
# ....
# #100 $finish
# end
#
init_Architecture() {
_module_ = Module({name:Sample});
_a_ = _module_.Input.Signal([{name:a},
{length:32},
{cur:[{time:0},{val:x}]},
{nxt:[{time:0},{val:x}]}]);
_c_ = _module_.Output.Signal([{name:c},
{length:32},
{cur:[{time:0},{val:x}]},
{nxt:[{time:0},{val:x}]}]);
_clk_ = _module_.Clk.Signal([{name:Clk},
{length:1},
{cur:[{time:0},{val:x}]},
{nxt:[{time:0},{val:x}]}]});
_rst_ = _module_.Rst.Signal(...);
_b_ = _module_.Reg.Signal(...);
_method_0_ = _module_.Method([{{C1:{_rst_==1'b1}},{P1:{_b_=0}}},
{{C2:{_rst_==1'b0}},{P2:{_b_=_b_+1}}}]);
[_clk_,_rst_].set_Driver(_method_0_);
_method_1_ = _module_.Method([{{C1:{_b_==10}},{P1:{c=b+a}}},
{{C2:{_b_!=10}},{P2:{c=a}}}]);
[_b_].set_Driver(_method_1_);
[_clk_,_rst_,_a_,_c_,_b_].set_Parent(_module_);
[_method_0_,_method_1_].set_Parent(_module_);
gl_Module_List.push(_module_);
_module_.Signal_List.push([_a_,_c_,_clk_,_rst_]);
}
init_Time_Wave(){
_gl_clk_ = Clk([{start_time:0},
{end_time:100},
{period:10}]);
_gl_rst_ = Rst([{time: 0:F},
{time: 5:R},
{time: 20:F},
{time: 80:R},
{time:100:F}]);
_gl_time_ = Time();
}
run_gl_Module_List(time cur_time,
time nxt_time) {
schedule_list = [];
update_list = [];
# @ find the signals
foreach _module_ ( gl_Module_List ){
foreach _signal_ ( _module_.Signal_List )
if( _signal_.cur.time <= cur_time )
schedule_list.push(_signal_);
}
schedule_list.sort_by_time();
while( !schedule_list.empty() ){
_schedule_ = schedule_list.pop_left();
_driver_ = _schedule_.get_Driver();
method_list = _driver_.get_Methods();
foreach _method_ ( method_list )
update_list = method.run_Signal_update();
foreach _update_ ( update_list ){
Signal(_update_).cur.val = Signal(_update_).nxt.val;
Signal(_update_).cur.time = nxt_time;
Signal(_update_).nxt_time = nxt_time + nxt_time - cur_time;
if( Signal(_update_).get_Driver()!= Output ){
schedule_list.push(_update_);
schedule_list.sort_by_time();
}
}
}
}
run_Simulation(){
_gl_cur_time_ = _gl_clk_.start_time();
_gl_nxt_time_ = 0;
# check simulation time
while ( _gl_cur_time <= _gl_clk.end_time() ) {
_gl_nxt_time = _gl_cur_time_ + _gl_clk_.period()>>1; # @ posedge/negedge edge check
run_gl_Module_List(_gl_cur_time_,_gl_nxt_time_);
_gl_cur_time = _gl_nxt_time;
}
}
refs:
http://www.ocpip.org/datasheets.php
http://www.greensocs.com/
source code download
http://sourceforge.net/projects/greensocs/develop
訂閱:
意見 (Atom)